Feature Learning from Continual Learning
Continual Learning: learning to remember.
Feature learning: learning to understand.
I have always been curious about one thing: what makes neural networks so powerful? One of the sub-questions is: what do neural networks actually learn?
A very famous example I would like to use is self-attention: 
When generating words, the model concentrates on different parts of the picture, similar to how human would focus on.
But are all models learned in this way?
First, we need to remember what the models are doing. They are extracting features, discarding unneeded information (such as noise), and focusing on the valuable content. This valuable content is then fed into the final fully connected (fc) layer, which acts as a classifier—the layer that learns the mapping between features and labels.
An Interesting Phenomenon
I was enrolled in an AI-related course at my school, and one of the projects was to do image classification on a dataset we collected ourselves. The dataset was extremely poor, and the data distribution was highly unideal. For example, a tin can could have a label of 'metal', 'waste', or even 'hazardous waste' if it contains outdated medicine. Let’s call it the UESTC dataset.
It seemed almost impossible for models to achieve good accuracy on such a dataset. Initially, I blamed the UESTC dataset and set it aside. Days later, a friend of mine told me he achieved a high accuracy of 80% using a pretrained model on ImageNet. This immediately drew my attention. By using a simple transfer-learning technique, the model could learn to classify the UESTC dataset with high accuracy. Surely, the pretraining experience on ImageNet helped the model learn to extract more general information, instead of focusing on minor details that were highly correlated with a specific dataset.
Now, I would describe this phenomenon as feature learning. In fact, I believe one of the most important aspects of transfer learning is feature learning. The teacher model is pretrained on a high-quality dataset, where it learns to extract features. These pretrained parameters can then be transferred to a downstream task as initialization. This starting point of gradient descent significantly influences the entire process and most likely leads to better performance.
So naturally, I thought about training the model on the UESTC dataset to improve its generalization, hoping it might then perform better on ImageNet. However, I tried and failed. The model trained on the UESTC dataset forgot about ImageNet, resulting in overfitting on the UESTC data.
Continual Learning
As we can see, this method only improves accuracy on a specific dataset. Once we start training the model on the downstream task, the parameter space begins to shift, and it loses its generalization ability. Like this graph:
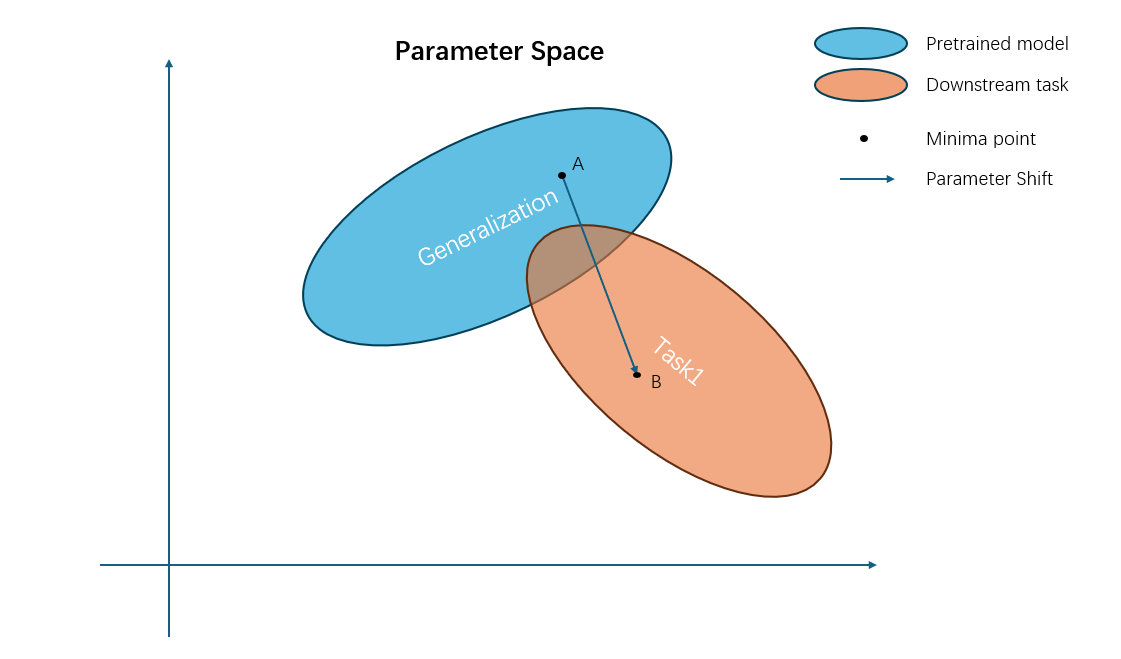
What if we want this model to learn and remember? Is it possible to keep the parameters in the "sweet spot," where the model can balance the trade-off between performance and overfitting? It is possible, and this problem is known as the continual learning problem.
Continual learning techniques can help alleviate the phenomenon of catastrophic forgetting, which refers to the model forgetting previous tasks when training on later tasks.
Another concept, though related, is called Lifelong Learning. This aims to achieve a learning process similar to that of humans—learning forever while continuously remembering the most important information.
Below, I will briefly introduce some popular continual learning techniques.
-
Adding Constraints: such as EWC, OWM, GPM
These techniques add constraints to the loss function. The constraints can be related to the mean, gradient, or variance of parameters. The goal is to create a gradient map where the minima lie in the sweet spot.
-
Dividing Models: such as HAT
This is a tricky but unsustainable technique. It divides a model into different parts, with each part responsible for a specific task. However, this does not suit the goal of lifelong learning, as the model will quickly run out of free space. I also want to emphasize that short-term continual learning is easy but unimpressive. 📌 I will explain why below.
-
Memory Pool: such as A-GEM
This method requires an additional memory pool to store previous gradients or data. Occasionally, the model revisits the memory pool and attempts to "review" previous knowledge.
Surprising performance of feature learning
Before beginning, I want to say that this part in my opinion only, and it might be naive or not mature. Perhaps I did not get the gist of Continual Learning, and perhaps I will change my mind later, but it would not hurt to record and share my current thought, even if it might be wrong.
What attracts me to continual learning is its motivation—i.e., learning to remember. To prevent catastrophic forgetting, the ideal approach is to learn the general rules of data, without over-concentrating on minor details, like human learn. We never remember what we have eaten in the previous days, but knowledge we learnt will be kept in our mind for a long time. We know what to focus and what not to focus. We know how to distill useful information.
However, the techniques I’ve presented above do not consider data distillation at all. There is nothing about feature extraction or generalization. They focus primarily on reducing conflict during each training process. It’s like a double-edged sword. Perhaps in some scenarios, these techniques may work better, but at least for their baselines (which are typically tested on split-CIFAR100 or P-MNIST), they are somewhat less effective. Why do I say this? Because traditional backpropagation (BP) can already do just fine.
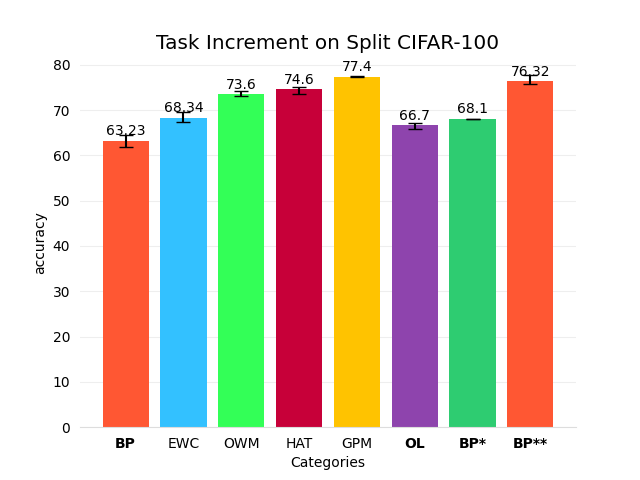
BP* refers to loading the model with the highest validation accuracy for each task.
BP** refers to freezing the feature extractor, which consists of the parameters before the classifier.
OL: a bottom to top training method using unsupervised orthogonal loss
Orthogonal loss: Given an output matrix of each layer \( Y \), the orthogonality loss is defined as:
\[ \mathcal{L}_{\text{ortho}} = \left\| \mathcal{N}(Y) - I \right\|^2_F \]where \( \mathcal{N}(Y) \) represents the normalized kernel of \( Y \), computed as:
\[ \mathcal{N}(Y) = \frac{Y}{\|Y\|_2} \cdot \left(\frac{Y}{\|Y\|_2}\right)^T \]Here, \( I \) is the identity matrix and \( \|\cdot\|_F \) denotes the Frobenius norm, which measures the difference between the normalized covariance and the identity matrix.
Are these results surprising? They have been tested across five different seeds, which should be sufficient to draw meaningful conclusions. While BP is highly unstable in continual learning (and in some cases, it may completely forget previous tasks—naturally, I did not include those seeds in the baseline), some of its transformations reach remarkably high accuracy.
Why does BP** achieve such outstanding performance? The reason is straightforward: at its core, BP** is not true continual learning. For each task, only a single fully connected (fc) layer is trained, while the previous parameters remain frozen. But let’s consider it from the perspective of feature learning. Similar to the case of the UESTC dataset, the training of task 1 acts as a pretraining phase, while subsequent tasks function as downstream tasks. Pretraining on task 1 helps the model learn effective feature extraction, which in turn benefits the training of the fc layer in later tasks.
📌: This is why I argue that achieving short-term continual learning carries little significance—BP already performs quite well in this regard, sometimes even surpassing advanced techniques like HAT.
Why does OL achieve a satisfactory accuracy with no supervise signal and a weird looking loss? The reason is, Orthogonal loss is actually feature learning. Let us revisit orthogonal loss, what is it? Essentially, OL encourages the model to increase the rank of the output features, meaning it maximizes the amount of information retained in the learned representations. The higher the rank, the richer the feature set. So, instead of letting the model learn to extract feature by itself, I tell it what to do: simply just extract much information as possible, and leave the remaining task to classifier! Pretty much similar to things like PCA huh? a downsampling technique designed to preserve as much information as possible while reducing dimensionality. (I am proud of my instinct, I think this weird loss could work before I implemented this)
However, this only holds for task-incremental learning. When applied to class-incremental learning, BP and OL completely fails because the classifier becomes the limiting factor. Still, the underlying principle of feature learning remains unchanged.
Even in datasets like permuted-MNIST, where the data is randomly permuted and lacks generalizable features, BP** still achieves outstanding accuracy. The feature extractor adapts by increasing the rank of the feature matrix, thereby expanding the parameter space and retaining more useful information.
A Remarkable but Flawed Method: HAT
When I first implemented HAT, its performance left me completely astonished. It simply does not forget.
However, this comes at a cost. One peculiar issue is its incompatibility with BatchNorm, along with a strict learning rate limitation of 5e-2. A standard toy model that performs well with other techniques must be specifically adjusted to work with HAT. The incompatibility with BatchNorm significantly restricts HAT’s ability to scale to larger models due to potential numerical instability.
But that’s not the only drawback. A fundamental issue with HAT is its architecture, which essentially partitions the model into num_classes segments. When making a prediction, the model activates only a specific portion of itself. While this mechanism effectively prevents forgetting, it raises concerns when handling a large number of tasks—or even an infinite number, as defined in lifelong learning. In practice, our toy model failed on split-Tiny-ImageNet when using HAT, despite performing flawlessly with other methods.
Conclusion
I believe a promising direction for continual learning should align with human learning principles—focusing on understanding rather than mere memorization. In other words, leveraging feature learning to achieve continual learning would be a far more effective approach.