我对 ResNet 与 BatchNorm 的一些理解
跳跃连接(skip-connection)和各种归一化(包括 BatchNorm)几乎出现在所有现代神经网络中。 但不少论文在使用这些技术时并不严谨,反而增加了模型的不必要复杂度。 所以回到基础、重新理解它们,对做实验和思考理论都很重要。
Batch Normalization(BN)的可能优势
1. 提升数值稳定性
考虑一个用于回归的一层线性神经网络。其输出 \( o \) 与 均方误差(MSE)损失 定义为:
其中:
- \( W \in \mathbb{R}^{m \times n} \) 为权重矩阵;
- \( X \in \mathbb{R}^{n \times 1} \) 为输入向量;
- \( Y \in \mathbb{R}^{m \times 1} \) 为目标输出;
- \( \sigma(\cdot) \) 为激活函数。
损失对权重的梯度为:
其中 \( \odot \) 表示逐元素相乘,\( \sigma'(WX) \) 为激活函数的导数。
如果网络有 \(N\) 层,那么第一层的梯度大致为:
这串连乘项很容易趋近于 0 或无穷大,也就是我们熟悉的梯度消失 / 爆炸问题,本质上是一种数值不稳定性。
加入 BN 后,我们可以将每一层的输入 \(x\) 约束到某个高斯分布附近,从而缓和 \(x\) 和 \(\sigma'\) 的数值范围,减轻数值不稳定。
2.(也许并不)缓解 Internal Covariate Shift(ICS)[1]
在 BN 原始论文中,作者提出了 Internal Covariate Shift(内部协变量偏移,ICS)的概念:
ICS 指的是:由于前面层参数的更新,导致某一层输入分布不断发生变化的现象。
形式化地,每一层可以写成:
也就是说,网络每一层都在学习从输入模式 \(X\) 到输出模式 \(Y\) 的映射 \(\mathcal{F}\)。如果输入分布一直在变,那么这个映射就会被不断“扰动”;梯度也会随之变化,进而影响训练稳定性。
从这个角度看,ICS 被认为会妨碍训练,而 BN 通过“重新标准化”每一层的输入,似乎在一定程度上减弱了 ICS。
但我更喜欢从经典机器学习的角度来理解:我们通常假设数据是 IID 的(独立同分布),这是最大似然估计(MLE)以及各种损失函数推导的基础。BN 某种程度上让各层看到的数据更加“同分布”,这可能帮助网络获得更好的泛化性能。
不过,也有研究表明:BN 实际上并没有明显减弱 ICS,而 ICS 本身对性能也没那么关键。 他们更倾向于用别的视角解释 BN 的有效性。
3. 更平滑的损失曲面 [2]
有工作通过理论与可视化展示了:BN 会让损失曲面变得更加平滑:
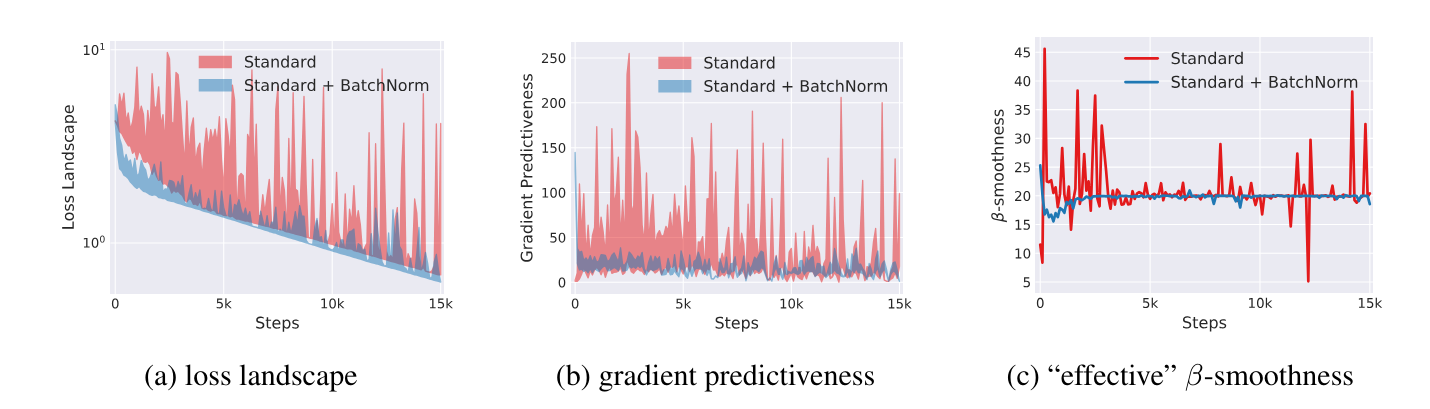
更平滑的损失曲面意味着梯度下降更容易“走得动”,不那么容易卡在又窄又尖的极小值里。这样一来,我们可以使用更大的学习率,加快收敛,同时不太牺牲泛化。
4. 更充分地利用非线性 [3]
注意,在对特征图 \(x\) 做完标准化之后,BN 还会再做一次线性变换(缩放与平移):

假设我们使用 sigmoid 作为激活函数:
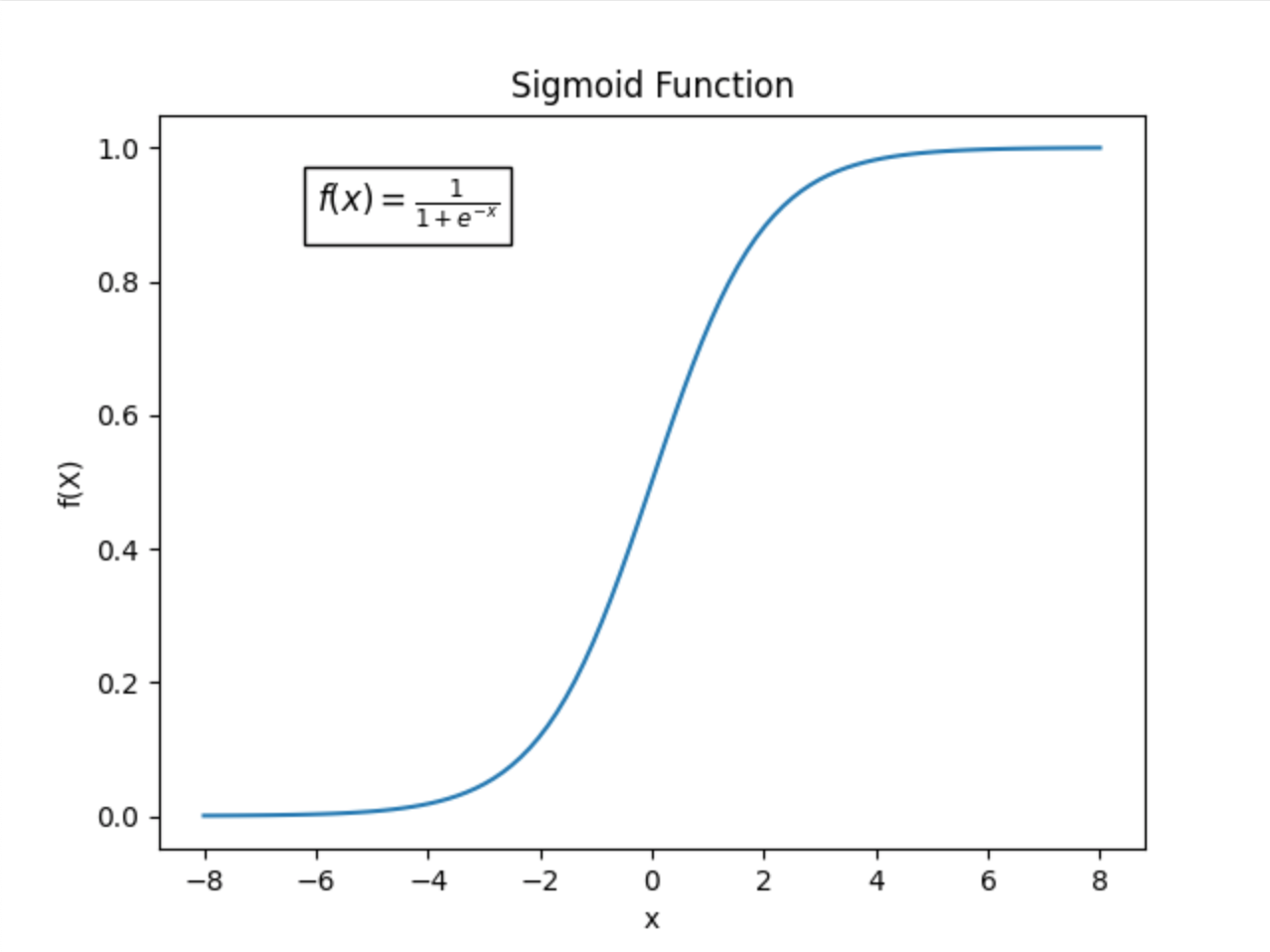
可以看到,当 \(x \in (-1, 1)\) 时,\(\sigma(x) \approx x\),也就是说非线性几乎退化成恒等映射。这显然不利于提升模型表达力。
通过 BN 后接的缩放和平移,我们可以把输入重新拉伸到更“利用”激活函数非线性的区域,使得网络真正发挥非线性模型的优势。
即便是 ReLU,看起来没那么脆弱,但如果某个神经元总是 \(x > 0\) 或总是 \(x < 0\),它要么变成线性单元,要么几乎不起作用。BN 的缩放和平移也有助于缓和这种情况。
当然,从我的视角看,这可能并不是 BN 最核心的贡献。一些实验甚至发现,把 BN 放在激活函数之后,有时效果会更好。
Skip-Connection 的可能优势
1. 让梯度流动更顺滑
ResNet 的作者 He 等人在 [4] 中指出,跳跃连接的一个关键好处在于改善梯度流动。对于一个带有残差连接的层:
其梯度为:
有了残差结构,梯度中总会多出一条“恒等映射”的通路,使得梯度不至于在传播中快速消失。
2. 缓解网络退化问题
在 ResNet 的原始论文中,作者提出了“网络退化问题”:
当我们把网络堆得更深时,即便没有明显过拟合,测试集精度有时反而会下降。
直观讲,如果更深的网络表现得比浅层网络还差,那说明“额外的那几层”还不如一个简单的恒等映射。于是他们引入了 skip-connection,把“恒等映射”硬编码进网络结构里,让更深的网络至少可以退化成“若干层恒等映射 + 一个浅层网络”。
真正有趣的问题是:网络退化的本质原因到底是什么?是否真的是“学不好恒等映射”?这一点目前仍然有不同观点,后续不少工作都在尝试给出新的解释。
梯度相关性视角 [2]
Balduzzi 等人在 [2] 中提出了另一个角度:他们认为 ResNet 缓解了所谓的“shattered gradients”问题,并用自相关函数(ACF)来量化梯度的“平滑程度”。
shattered gradients 指的是:相邻样本点的梯度几乎互不相关, 这会让很多假设“邻近点梯度相似”的优化算法(如带动量的方法)变得低效。
在强假设下,他们证明并实验展示了:skip-connection 可以提高梯度的 ACF,从而减轻 shattered gradients 问题。不过他们的假设有点强,我个人对这一解释持保留态度。

参考文献
[1] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.
[2] How Does Batch Normalization Help Optimization?
[3] The Shattered Gradients Problem: If ResNets Are the Answer, Then What Is the Question?
[4] Identity Mappings in Deep Residual Networks.